 ITとCFD入門サイト
ITとCFD入門サイト 
今回はMPIについて解説します。
MPIはMessage Passing Interfaceと呼ばれる並列計算の規格です。
異なるマシン(ノード)間で計算を行う際に利用される機能であるため、サーバにおける大規模計算にはMPIが利用されます。
2005年頃からシングルコアの性能が飽和してしまっている現代においては、並列計算は非常に強力かつ注目も高い技術です。
今後も重要なスキルになると思うので、ぜひ理解しておきましょう。
MPIとメモリ
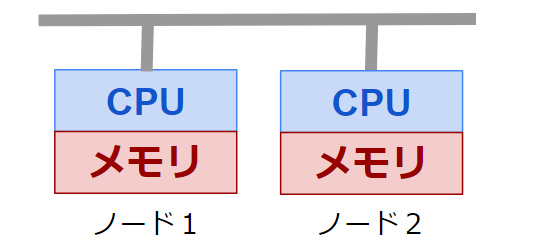
MPIは、分散メモリと呼ばれる構成に対して利用されます。
分散メモリはCPUとメモリが一対一のペアとなった状態で、そのペアが同一のネットワークにある状態のことです。このペアのことをノードと呼びます。
MPIはSIMD(Single Intruction Multiple Data Stream)と呼ばれる複数のデータに対して一つのプログラムから命令がくだされます。
ただし、同じ命令と言ってもプロセスごとに別の配列を参照するので、厳密にはプロセスごとに別の処理が行われます。
(そのため、MPIはMIMD(Multiple Intruction Multiple Data Stream)と呼ばれることもありますが、プログラムはひとつなのでSIMDとして理解したほうがわかりやすいです。)
ノード内並列のように同一のメモリを参照する場合は「マルチスレッド」と呼ばれ、OpenMPがこれに当たります。
一方で、ノードをまたぐような別メモリの場合は「マルチプロセス」と呼ばれ、MPIはこちらに分類されます。
よって、マシン(ノード)内はOpenMP、マシン(ノード)間はMPIと両方を使うことで、大規模計算を実現できます。
並列計算
基本的に、並列しやすいところだけが並列計算されます。
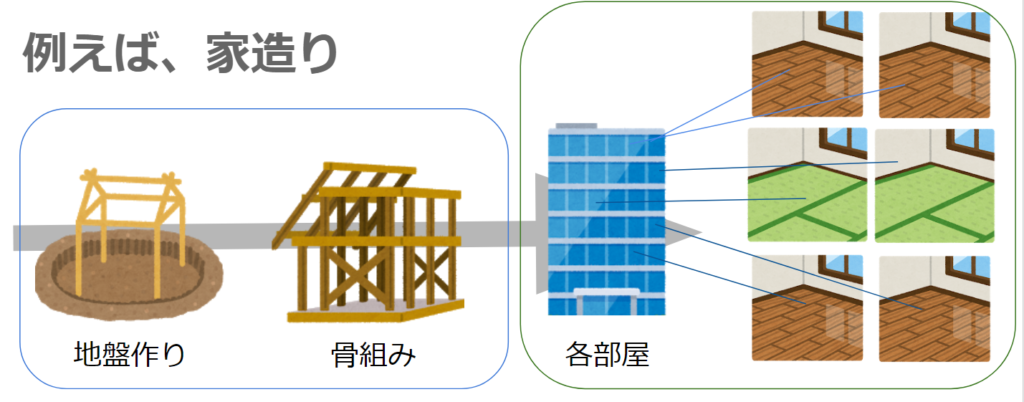
家造りに例えると、土台は逐次計算しないといけませんが、各部屋は並列で進められるといった具合です。
プログラムで考えると、プログラム内のforループ部分だけといったように、非常に計算時間がかかっている一部分を並列計算します。
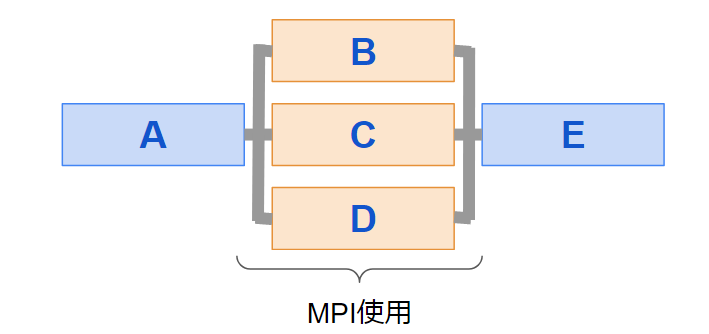
つまり、並列計算を使用してもコア数だけ高速化されるわけではありません。
プログラムの内容、つまり並列部分の多さによって並列化の効率が変わってくるので注意しましょう。
このような、並列しやすさのことをスケーラビリティと呼びます。
MPI
よく使われるMPIソフトウェアは下記の通りです。
- MPICH :メジャー
- OpenMPI:メジャー
- MVAPICH:GPUに強い
上2つが最もメジャーなMPIソフトウェアです。
基本的にどれを使っても同じような結果になるので、どれを選んでも大丈夫です。
例えば、MPICHによりMPIのプログラムをコンパイルするには、mpiccコマンドを使います。
mpicc -o mpi_exe mpi_program.c上記により、mpi_program.cというプログラムから、mpi_exeという実行用ファイルを作成することができます。
c++では「mpic++」によりコンパイルできます。
実行はmpirunで行います。
mpirun -np 8 ./mpi_exe上記ではnpで並列数を指定しており、8並列で計算が行われます。
ノードの指定には -host を使用します。
mpirun -host node1,node2-np 8 -ppn 4 ./mpi_exe-ppnにて各ノードの並列数が指定されます。
MPIプログラム(基本)
下記にサンプルプログラムを示します。
ここでは基本となる最低限のプログラムを示しており、データ交換を行っていません。
#include <stdio.h>
#include "mpi.h"
int main(int argc, char +argv[]){
int nproc,rank;
MPI_Init(&argc, $argv);
MPI_Comm_size(MPI_COMM_WORLD, &nproc);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
printf("%d in %d", rank, nproc);
MPI_Finalize();
return 0;
}まず、mpiの使用にはmpiライブラリのインクルードが必要です。そこで、2行目でmpi.hののインクルードを行っています。
main関数内で出てくる大文字MPIから始まるのが、MPIのAPIです。
これらAPIを用いて多数のプロセスを管理します。
MPIの使用には、5行目のMPI.Initによる初期化と9行目のMPI.Finalizeによる終了が必須です。
この間でMPIのAPIが使用可能になります。
6行目のMPI_Comm_sizeはプロセス数を取得します。
第一引数のMPI_COMM_WORLDはMPI全体を表す変数で、第二引数のnprocにプロセス数を与えています。
7行目のMPI_Xomm_rankも似た機能で、こちらは各プロセスが担当する自分のプロセス番号が得られます。これによって全てのプロセスで異なる番号が得られることになります。
MPIでは自分のプロセス番号のことを「ランク」と呼ぶので、覚えておきましょう。
MPIプログラム(データ交換)
データ交換において重要なのは、①送信(send)、②受信(Recv)、③待ち(Wait)の3つです。
MPIでは送信と受信がマッチしていないと通信されません。
よって、うまくプログラムが流れるように頭で考えながら、適した位置に命令を配置してやる必要があります。
もしミスによりお互いが受信待ちになってしまうと、処理が全く進まない「デッドロック」と呼ばれる現象が発生します。
送信(Send)
データを他のプロセスに送るためのAPIとして、MPI_SendとMPI_ISendがあります。
MPI_Sendは送受信が確定するまで待機するというブロッキング通信です。
プログラムの流れに沿って順番に実行されるため、予想外のことが起きにくいという特徴があります。
一方で、MPI_ISendは送信命令を出しながら次の処理を進める非ブロッキング通信です。
待ち時間がないので効率的ですが、予想外のデータ更新が起きないようにMPI_Waitにより同期のタイミングを適切に与える必要があります。
例えば、MPI_Sendは下記のように書けます。
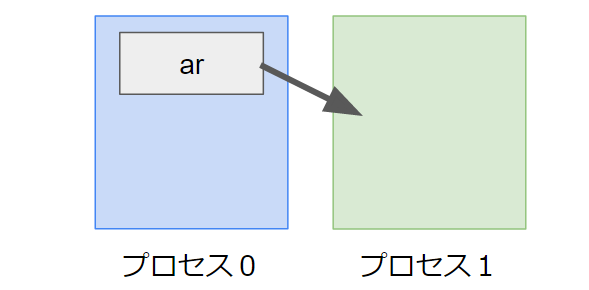
int ar[10];
MPI_Send(ar, 10, MPI_INT, 1, 0, MPI_COMM_WORLD);MPI_Sendの引数は、左から順に「贈りたい配列の先頭アドレス」「要素数」「型」「受け取り側のランク(プロセス番号)」「タグ(任意の識別番号)」「MPI_COMM_WORLD」となっています。
これによりランク1のプロセスに対して配列arを送信できます。
MPI_Isendもほぼ同じ引数構成で、最後にWait用の識別子をつけるだけです。
MPI_Request send_request;
int ar[10];
MPI_Send(ar, 10, MPI_INT, 1, 0, MPI_COMM_WORLD, &send_request);受信(Recv)
受信も送信と形式はほぼ同じです。
他のプロセスの送信と同時に行われることで、初めてデータの通信が成立します。
受信も送信と同じく、ブロッキング通信であるMPI_Recvと非ブロッキング通信であるMPI_Irecvに分けられます。
MPI_Recvは下記のように書きます。
int ar[10];
MPI_Recv(ar, 10, MPI_INT, 0, 0, MPI_COMM_WORLD);これによりランク0のプロセスから配列arを受け取れます。
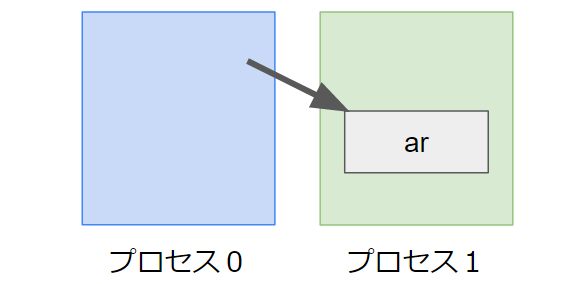
非ブロッキングのMPI_Irecvだと下記のようになります。
MPI_Request recv_request;
int ar[10];
MPI_Send(ar, 10, MPI_INT, 0, 0, MPI_COMM_WORLD, &recv_request);待ち(Wait)
ブロッキング通信を使うときも非ブロッキング通信を使うときも、ノード間の進行を一致させたいときは出てきます。
例えば、全てのデータが揃ってから進めたいときは、プロセス3,4が追いつくまでプロセス1,2を待たせておきたいといったことがあります。
こんな解きに使うのが「同期」です。同期によりほかのプロセスを待つことができます。
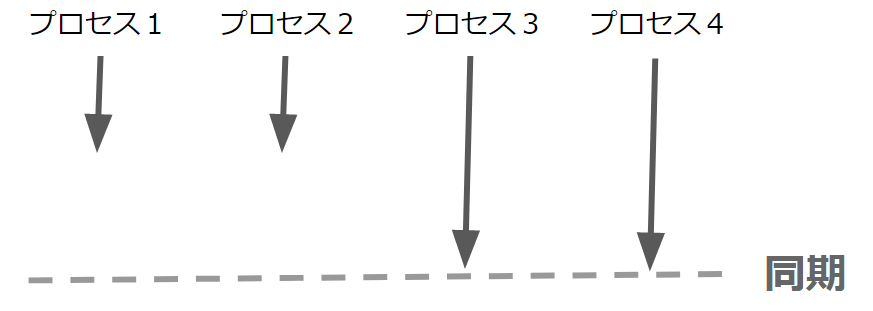
全てのノードを同期させる場合は、下記のMPI_Barrierを使います。
MPI_Barrier(MPI_COMM_WORLD);これを送受信のあとに入れることで、ノードの進行を合わせることができます。
非ブロッキングの場合は、WaitもしくはWaitallを用います。これらは指定のリクエストのみを同期させることができます。
Waitallは下記のように使用します。
MPI_Request send_request, recv_request;
・・・
MPI_Isend(・・・, &send_request);
MPI_Irecv(・・・, &recv_request);
MPI_Waitall(1, &send_request, MPI_STATUS_IGNORE);
MPI_Waitall(1, &recv_request, MPI_STATUS_IGNORE);上記のプログラムでは、1つ目のWaitallで全ノードのIsendを待ち、2つ目のWaitallで全ノードのIrecvを待っています。
MPI_Waitallの引数は左から順に、「リクエストの個数」「リクエストの先頭アドレス」「ステータス」です。
リクエストとは、IsendやIrecvの末尾につけた識別子のことで、これらと対応しています。
ステータスは基本はMPI_STATUS_IGNOREで良いです。
ただし、上記だと2回Waitallを書く必要があって面倒です。そこで、配列を使用してWaitallを短縮しましょう。
MPI_Request request[2];
・・・
MPI_Isend(・・・, &(request[0]));
MPI_Irecv(・・・, &(request[1]));
MPI_Waitall(2, request, MPI_STATUS_IGNORE);このように配列をIsendとIrecvに割り振ることで、一度のWaitallで全ての通信を回収できます。
おわりに
今日はMPIに最低限必要な知識とAPIについて紹介しました。
重要なポイントは以下の通りです。
- MPIはノード間並列を担う
- ノード内並列はOpenMP、ノード間はMPIで並列化する
- MPIでは送信、受信、待ちの3つが重要である
- 基本はMPI_Sendで送り、MPI_Recvで受け取り、MPI_Barrierで同期する
- 通信待機するブロッキング通信と、処理を進める非ブロッキング通信がある
MPIはコツさえわかってしまえば核の部分の理解は意外と難しくありません。
ただしここで紹介したAPIはごく一部の基本なので、他にも膨大なAPIが存在します。
基本を習得して、さらに足りない機能を感じたら検索をかけてみると良いでしょう。
並列計算は非常に強力な技術であり、2005年頃からシングルコアの性能が飽和してしまっている現代において注目が高まり続けています。
今後も重要なスキルになると思うので、ぜひ理解しておきましょう。
youtubeもやってます
並列計算とは少し異なりますが、Linuxの基本知識について動画でも解説してます。よければどうぞ。

